 2025
2025- 2024
- 2023
- 2022
- 2021
- 2020
- 2019
- 2018
- 2017
- 2016
- 2015
- 2014
- 2013
- 2012
- 2011
- 2010
- 2009
- 2008
 2007
2007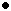 Sequence Converter
Sequence Converter- Widgetless
- Visa Swap
- Voxel Brain
- Quake
- Prefix Matching
- 12 Girls Band
- Waves to Wine
- Sphere Builder
- SF Panorama
- Global Warming
- Cycling at Mach 1
- First Steps
- Power
- Who Gadget
- Transposing Diffs
- Bike to Work
- Google Code
- Spaghetti Monster
- Visitors
- Maker Faire 2007
- Brave New World
- 420
- COMP2405
- H-1B Visa
- Mandelbrot Scroll
- Carved Links
- New Page
- Moo Inspector
- Fridge Letters
- Vet Tax
- Boredom and Frustration
- Crescent Moon
- Nesting
- Queen Mary 2
- Social Security
- SketchUp
- San Francisco
- Traffic Bugs
- 2006
- 2005
- 2004
- 2003
- 2002
Prefix Matching
9 October 2007
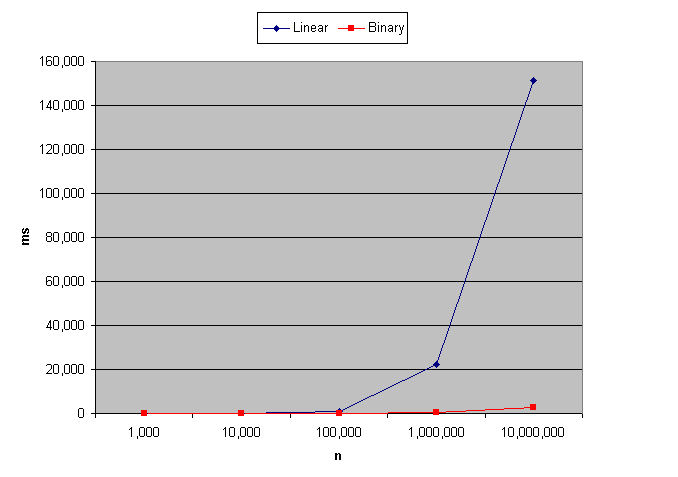
The common prefix and suffix algorithms in my Diff, Match and Patch library uses a binary search of substrings to locate the divergent point. I claim this to be O(log n) instead of O(n). In the year since this was first published I've been taking a lot of heat from programmers who look at the algorithm and realize what the substring operation is doing at the processor level. They write back, call me up, or burst our laughing when they realize that my 'optimization' actually evaluates to O(n log n). I patiently explain that high-level languages don't work that way, but the skeptics remain unconvinced.
Fine, let's look at some data. Here's a bake-off between the standard linear O(n) approach and my unexpectedly controversial so-called O(log n) binary search:
And I've helpfully graphed the output on a logarithmic scale:
![[Graph of linear vs binary performance.]](/news/2007/prefix.gif)
Any questions?
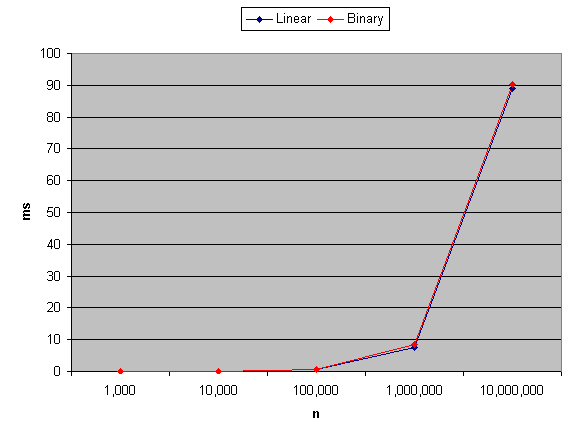
Update: Wondering how Java compares? bin_vs_lin.java reports that the binary and linear approaches are virtually identical when graphed against each other. Also interesting is what it looks like when graphed on the same scale as the above JavaScript.
{kind=link}
{kind=link}
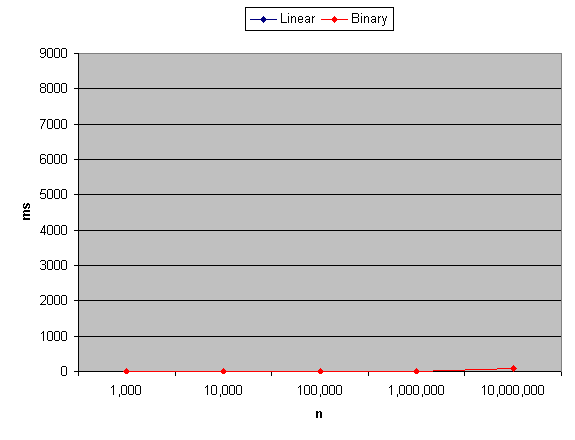
Update: Wondering how Python compares? bin_vs_lin.py reports that the binary approach is significantly faster than the linear approach when graphed against each other. The binary approach in Python is about the same speed as either approach in Java.
{kind=link}
Update: Wondering how Lua compares? bin_vs_lin.lua reports that the binary approach is significantly faster than the linear approach when graphed against each other.
{kind=link}
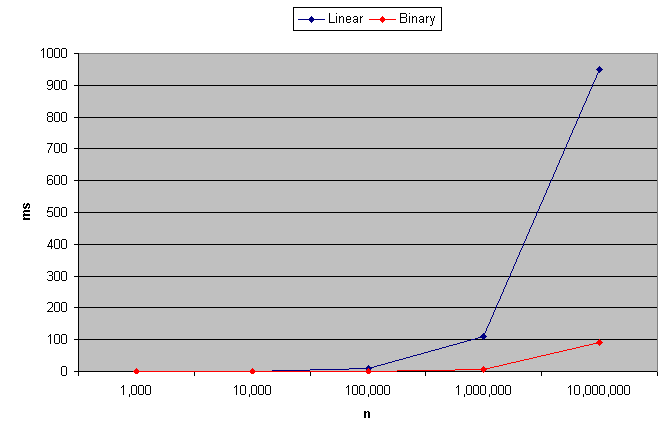
Update: Wondering how C# compares? bin_vs_lin.cs reports that the linear approach is significantly faster than the binary approach when graphed against each other. Unlike any other language tested so far, C# dies with an out of memory exception when generating a string of 1,000,000 characters. Both Microsoft's C# and the Mono compiler behaved the same.
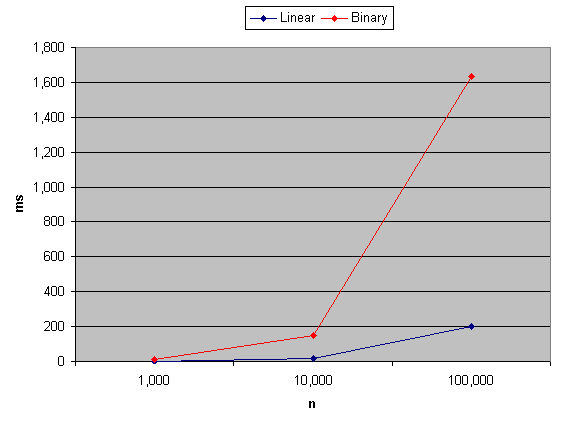{kind=link}
Update: This algorithmic analysis has generated a lot of interest. A Google engineer suggested the fastest algorithm yet:
"A cryptographer would tell you to call text1 == text2 and measure the time it takes to return an answer."While an engineer from another search engine company suggested the slowest algorithm yet:
var text = text1 + '\x00' + text2;
var m = text.match(/^(.*).*\x00\1/);
i = m ? m[1].length : 0;